Concurency and Parallelism

While concurrency and parallelism may sound similar (and in fact, are sometimes used interchangably both in normal and in computer contexts), the two terms actually are not the same. In this post, I will explain each of the terms’ origin, how different they are and why are they oftenly used incorrectly.
By its definition, a computer is a machine which computes, so it’s not a surprise that the CPU, which stands for central processing unit (and which we normally refer to as a computer chip) is the most important element of the machine. The part which deals with computational tasks inside a CPU is called the ALU (Arithmetic/Logic Unit), which basically computes everything in binary logic by lighting up some of its light bulbs and shutting down the others. It’s quite a simplified explanation of how CPU works, but the part we’re interested here is that at one particular time, it can only handle one computation, hence it computes and transfers the data back-and-forth to the memory (either the chip’s cache or the RAM) continuously. That means that by design, CPU computation is consequentially, and there’s no way we can expect to run two computations in the same CPU at the same time.
Since CPU time is valuable (you won’t be able to get back any second you let it rest), it’s best not to let it hang while we still have computations that need to be handled, but unfortunately, since the data is sequentially fed into CPU, if at some point the process is stuck by slowness in other components (memory, network, etc.), CPU will just rest. Provided that we still have many computations that need to be handled, those “rest time” is just wasteful.
For that reason, naturally people thought of preparing something for the CPU to do in its “free time”, and that’s what Operating System (OS) makes sure that the CPU works as much as it can by listing out the tasks that don’t need to be handled sequentially, and makes CPU jumps to the next task if its current one stops needing computing for a while.
Let’s illustrate it by taking an example, suppose we’re trying to compute the result of (9 + 3) * 15 * (7 + 2). This computation can be broken down as followed by the OS:
9 + 3(A)7 + 2(B)- Compute result of
Atimes 15 (C) - Compute result of
Btimes 15 (D) - Compute result of
Ctimes result ofB(E) - Compute result of
Dtimes results ofA(F)
We can see that A and B don’t affect one another, while C depends on A, and D depends on B. In turns, E depends on C and F depends on D, and only either C - E or D - F needs to be computed.
After being assigned number 9, CPU waits for + and 3 before it handles and sends back 12, suppose something happens and the command was not back fast enough, the OS moves CPU to task B, which assigns 7 + and 2 as a command. If anything happens during this process, the CPU can be shifted back to A, where it’s got all needed data to compute the number 12, which triggers C, and then E. However, if task B was assigned faster than A, B might be finished before A, and D - F will be triggered instead.
While A and B are processed at more or less the same time, we still can’t say that their computations were happening in parallel, since at any moment, the CPU only handles one of them. We also can’t say that A and B were processed sequentially, since one does not need the other to finish before it starts.
Here, we say that A and B were processed concurrently, but not in parallel. It means that any of them can start first, and any of them can finish first without affecting the other (note that the one which starts first doesn’t necessarily finish first, regardless of their sizes), but at one moment, only one of them can be handled, since the processing is done with a single CPU.
For easy remembering, concurency works like you make side-disk salad while waiting for your turkey. You normally start with preparing the turkey, and only after it was put into the oven, then you will start with the salad. At one time, you may only work on one of the disks, but it’s faster than waiting for the turkey to finish before starting on the salad. Depending on the complication level, you may finish the salad first or turkey first, but that certainly does not matter much.
Below is the illustrator of a possible scenario:
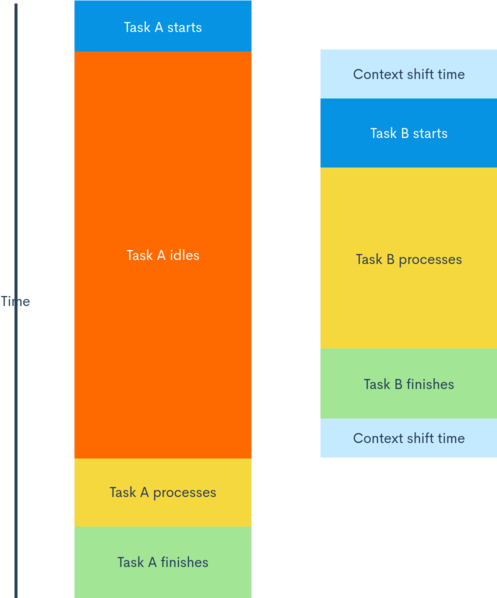
Then when is paralellism achieved?
It might be needed to reaffirm that there’s no parallelism in single CPU. At one particular point in time, one CPU can only handle one task. However, as you may have guessed, in the modern world, we have some new architecture called multi-core CPU, which is basically more than one CPU running at the same time. Each of them can handle one task, hence true parallelism can be achieved, as followed:
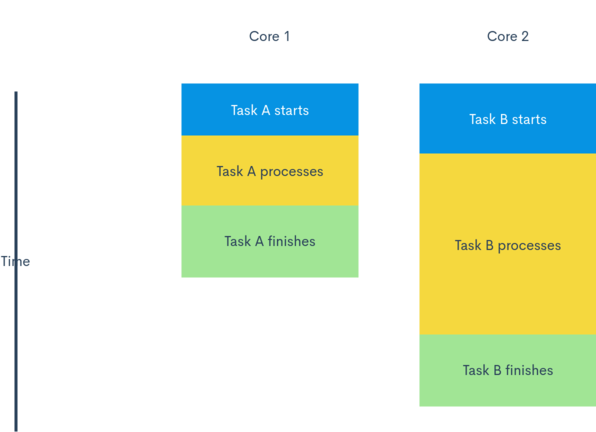
However, please note that even with multi-cores, the tasks that are running in parallel are still bounded by the rule: they must not depend on one another’s result. Coming back to the example we had earlier, it’s easy to see that we can’t make it faster by, say, running C and E concurrently, if E starts before C has been finished, it may default, or worse, it may pick either 12 (result of A) or 15 as it was what’s available on the memory. Therefore, it might not always make sense to increase the number of cores on the CPU (though the story is different for GPU, since image pixels can normally be handled fairly independently). With that said, multi-core processors still open up several possibilities for us, as programmers, to increase our program’s speed, but let’s talk about that later. For the time being, these are the few things we need to remember:
- Concurrency is the handling of more than one task in a independent manner, without any of the tasks depending on any of the other tasks’ results.
- Paralellism is the handling of more than one tasks at the same time, which can only be achieved by running each task on a different CPU.
- Paralellism is concurrency, but not vice-verse.
- The level of concurrency and paralellism is limited by several factors.